
Chen Zhang, Kuntai Du, Shu Liu, Woosuk Kwon, Xiangxi Mo, Yufeng Wang, Xiaoxuan Liu, Kaichao You, Zhuohan Li, Mingsheng Long, Jidong Zhai, Joseph Gonzalez, Ion Stoica Paper
出发点
CXL(Compute Express Link)是一种新兴的高速互连技术,旨在连接处理器、内存和加速器等组件。CXL内存可以被多个主机共享,提供了低延迟、高带宽的远程内存访问能力。然而,CXL内存也有一些局限性:
-
与DRAM的性能差距:CXL内存的访问延迟仍比DRAM高2-4倍,并且带宽只能达到DRAM单通道带宽的46%-70%,这意味着直接将数据放到CXL内存会造成性能降级。
-
有限的缓存一致性:现有的CXL原型只支持在一小块内存(几十到数百MB大小)范围内实现硬件缓存一致性(HWcc),意味着数据库的同步机制设计必须被重新考虑。
不过实际工程中,跨主机的事务(Transaction)往往只涉及少量的元组(Tuple),因此可以将这些活跃的跨主机元组放在CXL内存中,而将其他数据仍然放在DRAM中。这样可以充分利用CXL内存的低延迟和高带宽,同时避免了CXL内存的性能瓶颈。
于是本文中,Tigon把CAT(Cross-host Active Tuples)保存在CXL内存中,将多个消息交换转换为数据结构操作,并使用原子操作、元数据和硬件缓存一致性来同步并发访问。
- Tigon是第一个利用CXL内存高效同步跨主机并发数据访问的分布式内存数据库
- Tigon解决了CXL内存的局限性,如较高的延迟、较低的带宽和有限的跨主机缓存一致性硬件支持
- Tigon有效地维护了CXL内存中的跨主机活动元组(CAT),减少了主机之间消息交换的需求
- Tigon使用原子操作、元数据和硬件缓存一致性来同步对CAT的并发访问
- Tigon解决了在本地DRAM和CXL内存之间移动数据时有效访问数据和提供事务语义的挑战
个人思考
- CXL 硬件限制,比如较高的延迟,较低的带宽,所以不能将所有数据都放在 CXL 内存中,而是将跨主机活跃元组(CAT)放在 CXL 内存中,其他数据仍然放在 DRAM 中。在我们虚拟化的场景下其实很自然的是将虚拟机的冷页放置在 CXL 内存中。
- 而当前有限的CXL硬件缓存一致性内存范围(几百MB):数据库同步结构必须重新组织,以适应这种新的内存架构。那么在UB中现在的缓存一致性是否存在限制?如果有的话,又应该如何通过软件的方式来规避这种限制?
-
CLOCK 策略和我们目前的冷页扫描 Accessed 位类似,都是通过扫描来判断哪些数据是热的,哪些数据是冷的。通过这种方式来决定哪些数据应该被移回 DRAM。
-
Tigon旨在利用CXL来优化跨主机的数据访问和同步。但是如果有一个非常优秀的数据分区算法,可以尽量减少跨主机的事务(似乎更为重要,当然完全避免跨主机事务是不可能的,因而Tigon也是一个很好的补充,通过去分布式,避免2PC)
论文实验setup使用了CXL 1.1的硬件,通过在单个连接到 CXL 1.1 内存模块的主机上运行多个虚拟机(VM)来模拟 CXL Pod。

由于 CXL 1.1 内存设备对其连接的物理机是缓存一致的,因此虚拟机之间的缓存一致性由硬件维护。
论文总览
背景与动机
传统分布式数据库往往采用Share-nothing架构,即将数据划分到不同机器,并尽量让每个机器执行的事务(Transaction)只处理自己本地的数据。然而,在执行跨分区事务(既同时需要多个机器上的数据的事务)时,这种架构不可避免地引入大量机器间通信的开销,并且需要二阶段提交(2PC)之类的协议来保证事务正确执行。即使在使用RDMA等高速网络技术进行加速的情况下,这些跨分区事务仍然会严重影响分布式数据库的性能。
本工作提出了一个新的分布式数据库设计思路:使用CXL内存而非网络来同步不同机器上的数据访问。相比基于RDMA的共享内存,CXL内存可以支持更低的访问延迟,并且高版本(3.0/3.1)的CXL硬件还支持在一定范围内保证机器间缓存一致性。通过将运行分布式数据库的机器连接到同一块CXL内存来组成一个CXL pod,不同机器可以通过CXL内存来更高效地共享和同步数据。下图简要描述了一个CXL Pod的拓扑结构。
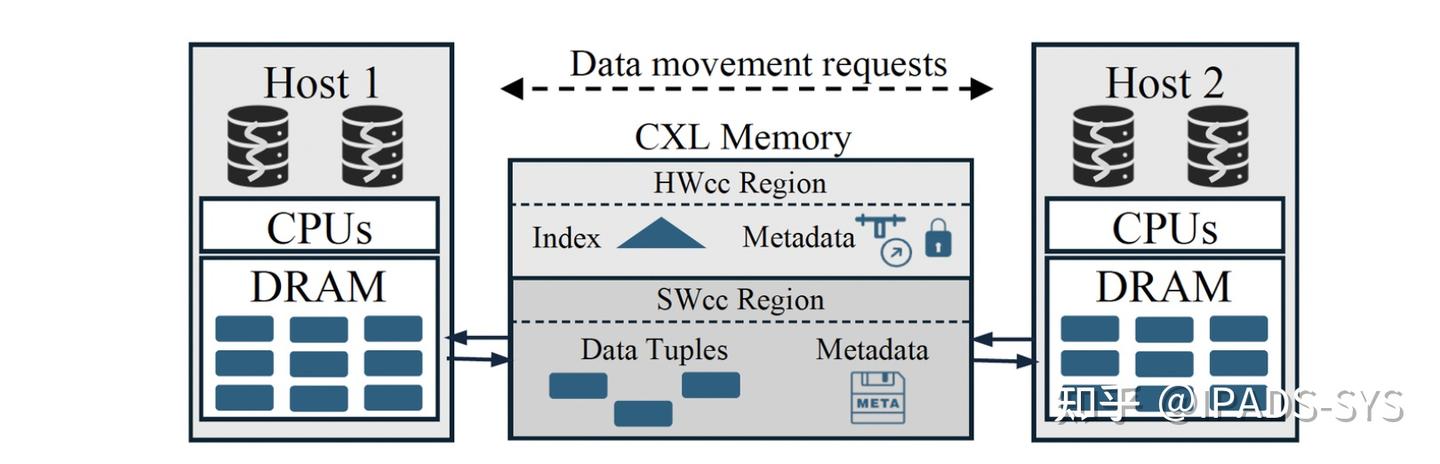
设计思路

为了克服这两个限制,本工作(Tigon)利用了一个关键洞察:会被不同机器上事务并发访问的数据元组(Cross-host Active Tuples,CAT)只占整个数据库的一小部分(其实也很显而易见,同时运行的事务数量不会超过数据库使用的CPU核总数,而每个事物一般只操作几个到几十个元组,论文给了具体的例子:TPC-C中,一个事务平均访问39个元组共7KB数据量,假设存在1000个核心,那么就是7MB数据量)。Tigon的设计会尽可能将CAT放置到CXL内存中,从而提升数据库性能。
具体地说,Tigon将数据库的数据划分到所有机器。在某个机器需要访问远程数据元组时,Tigon将该元组移动到CXL内存中。之后,跨机器的数据访问便可以使用原子操作和HWcc来完成,这使得Tigon可以采用单机的并发控制协议,避免2PC的额外开销。同时,每台机器仍可以从本地DRAM高效地访问属于自己分区的数据。
技术挑战与系统设计
Tigon的设计主要围绕解决两个技术挑战进行:
克服HWcc区域的容量限制:CXL内存只有一小部分支持HWcc,不足以放下所有CAT。如果采用换入换出的方式,则会引入大量CXL内存和DRAM之间的数据移动,影响性能。 高效和安全地访问移动的数据:CAT会在DRAM和CXL内存之间来回移动,如何高效利用CXL内存带宽并保证这种情况下数据访问的正确性是一大挑战。 为了解决挑战1,Tigon在非HWcc的CXL内存区域中实现了一层软件缓存一致性(SWcc)。
-
由于SWcc的数据访问性能要比HWcc差,Tigon将需要大量同步的数据库索引和锁等元数据放在HWcc区域,而将CAT中的数据元组放在SWcc区域。
-
在HWcc区域中,Tigon使用了一个SWcc bitmap 软件的方式来维护数据的一致性(每个Host对应一个bit,当设置了该bit时,表示该Host的CPU cache是最新的)。减少了锁和读取数据的开销。
-
由于Tigon采用两段锁进行并发控制,事务总会在访问数据元组前拿对应的锁。基于这个观察,Tigon根据锁所有权的传递进行SWcc区域中数据一致性的维护,减小了软件开销。
为了解决挑战2,Tigon采取了一系列数据结构和并发控制协议设计。
- 一个数据元组所属的机器会在本地的索引中缓存一个到HWcc区域索引中记录的指针,从而不经过HWcc区域中的索引即可在SWcc区域中定位到一个CAT,省去了查找过程的延迟和带宽开销。
- 采用两段锁协议和可扩展日志协议的协同设计,避免两阶段提交的使用。
-
在进行范围ca时,采用next-key locking技术解决范围查找中存在的幻觉(phantom)问题。
-
采用CLOCK策略来管理CAT的生命周期,避免CAT在CXL内存和DRAM之间频繁移动。类似于冷热页扫描 Accessed 位, 本文扫描clock 位,Tigon会定期扫描CAT,判断哪些元组是热的(频繁访问)并将其保留在CXL内存中,而将冷的元组移回DRAM。
操作系统角度思考
CXL内存在每个Host上都被视为一个CPU-less NUMA节点,Tigon通过修改内存分配器(如mimalloc)来将CXL内存区域集成到应用程序的内存管理中。这样,应用程序可以像使用本地内存一样使用CXL内存,而不需要额外的系统调用或复杂的API。
Tigon在每个Host上运行了一个专门用来接收移动数据到CXL内存的服务线程,以及多个Worker线程来处理事务请求和数据移动请求。通过实现一个lock-free多生产者单消费者(MPSC)环形缓冲区,Tigon可以高效地在CXL内存中传输数据。
Tigon为了减少HWcc内存的使用,通过设置CLOCK策略来管理CAT的生命周期,在Host侧设置一个周期性扫描任务来将冷数据从CXL内存移回DRAM。这样可以确保HWcc区域中的数据保持在一个合理的大小,同时仍然能够高效地访问热数据。
测试结果
本工作使用TPC-C和YCSB基准测试对Tigon进行了性能测试。测试中,Tigon相比使用CXL内存进行数据传递的Share-nothing分布式数据库(包括Sundial和DS2PL)提升了最多2.8倍吞吐,而相比基于RDMA的分布式数据库(Motor)提升了最多14.4倍吞吐。
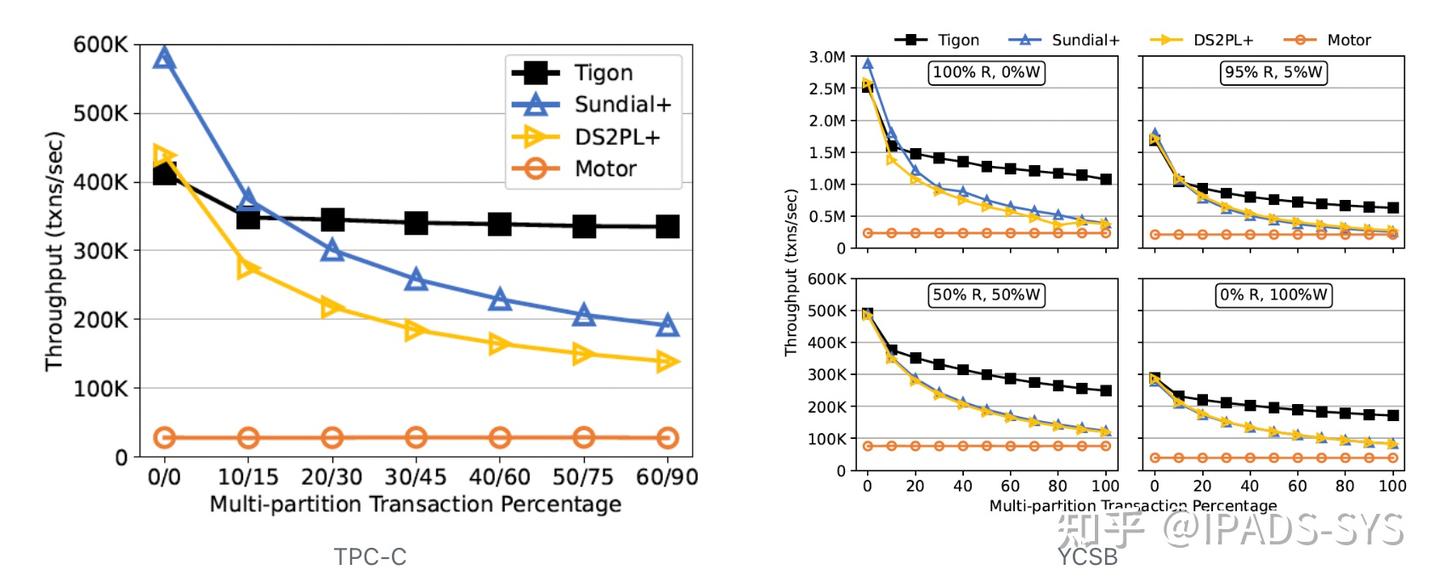
当不存在跨分区事务时,Sundial作为Share-nothing数据库表现出了强于Tigon的性能,因为它采用了更高级的并发控制协议。然而,当跨分区事务比例提升时,两个Share-nothing数据库的性能都出现了剧烈下降,因为它们需要频繁的跨机器数据交换,并且要用两阶段提交来保证事务语义。基于RDMA的数据库性能明显低于其他三个数据库,因为RDMA相比CXL有显著更高的延迟,并且本工作的测试环境中RDMA的带宽很低(25Gbps)。
Q&A
Q1: Tigon在容错方面是如何设计的?
A1: 技术方面讲,我们采取了出错-停止的错误模型,并用日志来保证我们能从错误中恢复。
Q2: 如何将Tigon扩展到更大的规模?
A2: Tigon的设计是针对CXL Pod的,因此它的规模被限定在单个机架内。
Q3: Tigon如何定位到数据?是有一个全局的索引还是?
A3: 我们有一个分区表用于确认数据位于哪个分区,然后每个分区有一个自己的索引来进一步定位到数据。
Q4: 对Tigon来说,选择正确的分区策略有多重要?
A4: 一个优秀的分区算法对于Tigon而言是非常重要的,它最好可以尽量减少跨分区的事务。
知识点补充
CXL
CXL(Compute Express Link)是一种高速互连技术,旨在连接处理器、内存和加速器等计算资源。CXL 1.1/2.0/3.0/3.1版本的主要区别在于支持的功能和性能改进。CXL 1.1引入了基本的内存访问和设备连接功能,而CXL 2.0增加了对多主机系统的支持,CXL 3.0进一步提升了带宽和延迟性能,并引入了更强大的缓存一致性机制。CXL 3.1则在此基础上进行了优化,提供了更高的带宽和更低的延迟。
总体来说,CXL 协议允许CPU 直接使用普通的加载和存储指令访问 CXL 内存,从而实现更高效的内存访问和数据共享。
局限性(相比于DRAM):
- 有着更高的访问延迟(214-394 ns vs 110—117 ns)
- 带宽限制:CXL内存的带宽通常低于DRAM,可能导致数据传输瓶颈。(只读任务下, 8-52 GB/s vs. 218-246 GB/s)
- 有限的CXL内存缓存一致性范围(几百MB):使得元数据的管理需要限制在这个范围内。
CXL内存用户态使用
CXL内存可以通过用户态的方式进行访问和管理。Linux内核提供了对CXL内存的支持,作为一个CPU-less NUMA节点暴露给用户空间应用程序。通过修改内存分配器(如mimalloc),可以将CXL内存区域集成到应用程序的内存管理中。
CXL pod
CXL Pod是一个由多个主机和一个共享的CXL内存组成的系统架构。
跨主机活动元组(CAT)
作为本篇论文的核心点,CAT是指在分布式数据库中被多个主机上的事务并发访问的数据元组集合。由于每个事务通常只会访问少量数据元组,因此CAT的大小通常远小于整个数据库的规模。
两阶段提交(2PC)
,两阶段提交(Two-Phase Commit, 2PC)是一种分布式事务提交协议,用于确保在多个参与者之间的事务操作的原子性和一致性。两阶段提交具体实现如下:
- 准备阶段(Phase 1):
- 事务协调者向所有参与者发送"准备"请求,要求参与者准备提交事务。
-
参与者执行事务操作,并将结果记录到日志中,但不提交。
-
提交阶段(Phase 2):
- 如果所有参与者都成功准备,事务协调者发送"提交"请求,参与者执行提交操作。
- 如果有任何参与者失败,事务协调者发送"中止"请求,参与者执行回滚操作。
需要两阶段提交的原因是:
- 在分布式系统中,多个参与者需要协调一致地提交或回滚事务,以确保事务的原子性。
- 如果只有一个阶段,无法确保所有参与者都成功提交或回滚,可能会导致数据不一致。
两阶段提交虽然可以保证事务的一致性,但也带来了一些性能开销,如需要两轮消息交换,以及协调者的单点故障问题。